1. 넘파이로 데이터 준비하기
이전 과정에선
파이썬 리스트를 순회하며 원소를 하나씩 꺼내 데이터를 생성.
하나의 길이와 무게를 리스트 안의 리스트로 직접 구성했음.
이젠 넘파이를 통해 훨씬 간편하게 생성 가능.
np.column_stack()
전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결.
파이썬 튜플(tuple)
튜플은 리스트와 비슷. 한 번 생성된 튜플은 수정 불가.
fish_data = np.column_stack((fish_length, fish_weight))
print(fish_data[:5])
'''
# 출력 결과
[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]]
'''
넘파이 배열을 출력하면 행과 열을 맞춰 정리된 모습으로 출력.
5개의 행과 2개의 열로 구성된 것을 쉽게 알 수 있다.
타깃 데이터 생성
이전 과정에서는 원소가 하나인 리스트 [1], [0]을 여러 번 곱해서 타깃 데이터를 생성했음.
하지만 넘파이 함수인 np.ones()와 np.zeros()를 이용하여
원하는 개수의 1과 0을 채운 배열을 생성할 수 있음.
#1이 35개인 배열과 0이 14개인 배열 생성
np.ones(35)
'''
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1.])
'''
np.zeros(14)
'''
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
'''
np.concatenate()
두 배열을 연결할 때, 차원을 따라 연결하는 함수 이용.
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
2. 사이킷런으로 훈련 세트와 테스트 세트 나누기
사이킷런
머신러닝 모델을 위한 알고리즘 뿐만 아니라 다양한 유틸리티 도구도 제공.
train_test_split()사이킷런의 함수로 전달되는 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어줌.
나누기 전 섞어도 줌.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state=42)
random_state=42
np.random.seed()와 같이 무작위로 섞기 전에 랜덤 시드를 지정하는 매개변수
train_test_split()은 기본적으로 25%를 테스트 세트로 구분.
print(train_input.shape, test_input.shape)
print(train_target.shape, test_target.shape)
'''
# 출력 결과
(36, 2) (13, 2)
(36,) (13,)
'''
훈련 데이터 36개
테스트 데이터 13개
입력데이터(훈련 데이터)는 2개의 열이 있는 2차원 배열
타깃 데이터(테스트 데이터)는 1차원 배열
print(test_target)
# 출력 결과 [1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
3. 수상한 도미 한 마리
k-최근접 이웃으로 훈련.
훈련 데이터로 모델 훈련하고
테스트 데이터로 모델 평가
from sklern.neighbors import KneighborsClassifier
kn = KneighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
print(kn.predict([[25, 150]])) # 출력 결과 1.0 → 빙어로 잘못 예측함.#[25, 150] 샘플 데이터를 다른 데이터와 함께 산점도 그려보기.
import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker=’^’)
plt.xlabel(‘length’)
plt.ylabel(‘weight’)
plt.show()
[25, 150] 샘플 데이터가 도미 데이터에 가깝다.
왜 이 모델은 빙어 데이터에 가깝다고 판단한 걸까?
kneighbors()
KneighborsClassifier 클래스의 메서드로, 주어진 샘플에서 가장 가까운 이웃을 찾아줌. 이 메서드는 이웃까지의 거리와 이웃 샘플의 인덱스를 반환. KneighborsClassifier 클래스의 이웃 개수인 n_neighbors의 기본값은 5이므로 5개의 이웃이 반환됨.
distances, indexes = kn.kneighbors([[25, 150]])
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker=’^’)
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker=’D’)
plt.xlabel(‘length’)
plt.ylabel(‘weight’)
plt.show()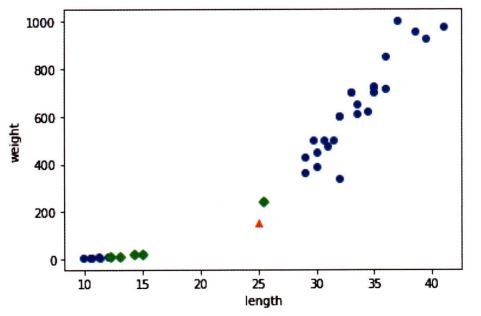
가장 가까운 이웃에 도미가 1마리 뿐.
print(train_input[indexes])
print(train_target[indexes])
'''
# 출력 결과
[[[ 25.4 242. ]
[ 15.19.9]
[ 14.319.7]
[ 13.12.2]
[ 12.212.2]]]
'''
[25, 150] 생선에 가장 가까운 이웃에는 빙어가 압도적.
왜 가장 가까운 이웃을 빙어라고 했을까?
print(distances) # 출력 결과 [[1. 0. 0. 0. 0.]]
4. 기준을 맞춰라
도미와의 거리 92
빙어와의 거리 130 이상
하지만 그래프 상의 거리 비율은 92 거리의 몇 배나 되어 보이는 거리에 130이 있음.
문제점
x축은 범위가 좁고 → 10~40
y축은 범위가 넓음 → 0~1000
따라서 y축으로 조금만 멀어져도 아주 큰 값이 거리가 됨.
plt.xlim()
x축의 범위 지정
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker=’^’)
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker=’D’)
plt.xlim((0, 1000))
plt.xlabel(‘length’)
plt.ylabel(‘weight’)
plt.show()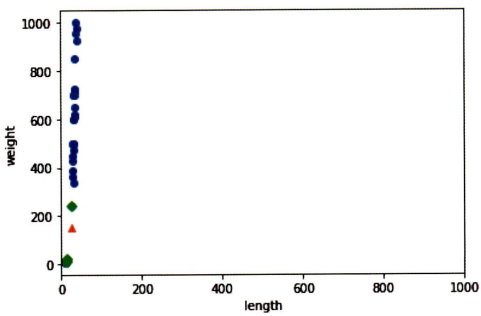
이 그래프로 보아
오로지 생선의 무게(y축)만 이웃 찾기 고려 대상이 됨.
길이와 무게의 특성이 다름.
데이터를 표현하는 기준이 다르면 알고리즘이 올바르게 예측할 수 없음.
알고리즘이 거리 기반일 때 특히!
k-최근접 이웃과 같은 알고리즘은
샘플 간의 거리에 영향을 많이 받으므로
특성값을 일정한 기준으로 맞춰 주어야 함. 이것이 데이터 전처리!
데이터 전처리 방법
표준점수(standard score, z 점수)
각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지 나타냄. 실제 특성값의 크기와 상관없이 동일한 조건으로 비교 가능.
분산
데이터에서 평균을 뺀 값을 모두 제곱한 다음 평균을 냄
표준편차
분산의 제곱근
np.mean()
평균
np.std()
표준편차
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_input의 크기는 (36, 2)
특성마다 값의 스케일이 다르므로 평균과 표준편차는 각 특성별로 계산.
이를 위해 axis=0 지정
print(mean, std) # 출력 결과 [27.29722222 454.09722222] [9.98244253 323.29893931]
# 표준점수 계산
train_scaled = (train_input – mean) / std # 브로드캐스팅(broadcastion) 됨.
브로드캐스팅(broadcastion)
크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능.
5. 전처리 데이터로 모델 훈련하기
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(25, 150, marker=’^’)
plt.xlabel(‘length’)
plt.ylabel(‘weight’)
plt.show()
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(25, 150, marker=’^’)
plt.xlabel(‘length’)
plt.ylabel(‘weight’)
plt.show()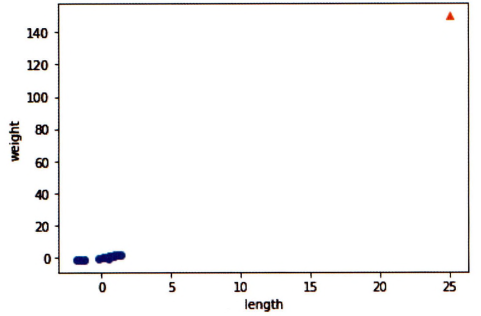
오른쪽 맨 꼭대기에 수상한 샘플이 덩그러니.
훈련 세트를 mean(평균)으로 빼고 std(표준편차) 나눠 주어
값의 범위가 크게 달라짐.
[25, 150] 샘플을 동일한 비율로 변환해야 함.
new = ([25, 150] – mean) / std
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker=’^’)
plt.xlabel(‘length’)
plt.ylabel(‘weight’)
plt.show()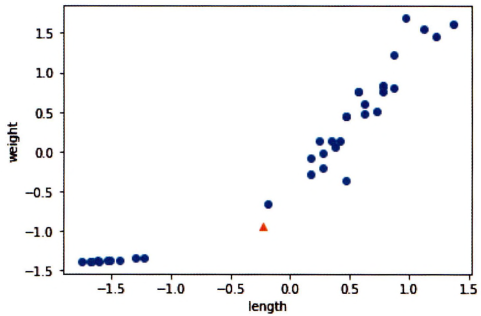
x축과 y축의 범위가 -1.5 ~ 1.5 사이로 바뀜.
훈련 데이터의 두 특성이 비슷한 범위를 차지.
kn.fit(train_scaled, train_target)
주의!
테스트 세트도 훈련 세트의 평균과 표준편차로 변환해야 함.
test_scaled = (test_input – mean) / std
kn.score(test_scaled, test_target)
print(kn.predict([new]))
test_scaled = (test_input – mean) / std
kn.score(test_scaled, test_target) # 1.0
print(kn.predict([new])) # 출력 결과 [1.]
# kneighbors() 함수로 [25, 150] 샘플의 k-최근접 이웃을 구한 산점도
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker=’^’)
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker=’D’)
plt.xlabel(‘length’)
plt.ylabel(‘weight’)
plt.show()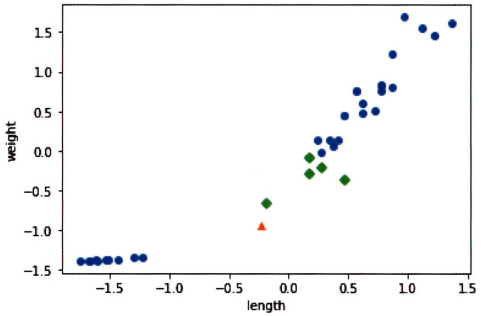
[25, 150]샘플과 가장 가까운 샘플이 모두 도미.
[정리] 스케일이 다른 특성 처리
길이와 무게의 스케일이 다름.
길이보다 무게의 크기에 따라 예측값이 결정됨.
특성의 스케일이 다르면 머신러닝 알고리즘은 작동하지 않음.
이 과정에서 특성을 표준점수로 변환.
특성 스케일을 조정하는 가장 대표적인 방법으로 표준점수.
scaled = (input – mean) / std
데이터 전처리 시 주의할 점은
훈련 세트를 변환한 방식 그대로 테스트 세트를 변환해야 함.
'머신러닝 > 혼공머신' 카테고리의 다른 글
| 혼공머신 | Chap 03-3. 특성 공학과 규제 (0) | 2022.08.24 |
|---|---|
| 혼공머신 | Chap 03-2. 선형 회귀 (0) | 2022.08.23 |
| 혼공머신 | Chap 03-1. k-최근접 이웃 회귀 (0) | 2022.08.22 |
| 혼공머신 | Chap 02-1. 훈련 세트와 테스트 세트 (0) | 2022.08.11 |
| 혼공머신 | Chap 1-03. 마켓과 머신러닝 (0) | 2022.08.08 |