판다스(Pandas)는
데이터를 조작 및 분석할 수 있도록 하는 라이브러리(library)이다.
흔히 엑셀(Excel)에서 볼 수 있는 형태로 생겼기 때문에
'굳이 판다스를 배워야할까? 필요할까?' 싶겠지만 필요하다.
엑셀에선 행이 최대 1,048,576개, 열이 XFD열까지가 최대이지만,
판다스에선 행의 개수나 열에 개수를 굳이 따지지 않아도 된다.
엑셀에서 불가능한 데이터량을 판다스로는 얼마든지 가능하다.
판다스 데이터 구조는 2가지이다.
1) 시리즈(Series)와 2) 데이터프레임(DataFrame)
이번 글에서는 시리즈(Series)를 공부하고,
다음 글에서 데이터프레임을 공부하자.
간단하게 말하자면,
시리즈(Series)는 한 줄짜리 김밥 같은 구조라면,
데이터프레임(DataFrame)은 2층 이상의 건물 같은 구조이다.
1. 시리즈(Series)

데이터베이스 관점에서
열(Column)이 하나만 있으면 시리즈다.
하나의 열(Column)에 하나의 행(Row) 값만 있어도 되고,
하나의 열(Column)에 여러 행(Row) 값이 있어도 된다.
열(Column)이 하나라면, 시리즈(Series)다.
'데이터베이스'관점이라고 한 이유는,
이때의 행은 하나의 데이터를 뜻하고
이때의 컬럼은 데이터의 속성을 뜻한다.
예를 들어 주식 종목 정보라고 한다면

종목명이 삼성전자인 가로(행, row) 정보들이 삼성전자 종목을 설명해주는 데이터인 것이다.
여기서 종목명, 현재가, 전일대비, 전일가 등이 열 혹은 속성이 된다.
종목명에 '삼성전자'와 'LG전자'가 와야하고
현재가에는 가격, 숫자 데이터가 들어가야한다.
현재가에 '삼성전자'라는 데이터가 들어가면 안되고,
종목명에 가격이 들어가면 안된다.
이렇듯 한 열에는 같은 의미의 데이터가 입력되어 있어야 한다.
데이터베이스 관점에선 이러하나,
판다스 시리즈에선 꼭 그렇지 않았다.

NAME이 HacadeMi이고
AGE가 100인
딕셔너리 데이터를 시리즈로 만들었더니 오류 없이 생성되었다.
아무튼 한 줄짜리 데이터가 시리즈인 것이다.
이럼에도 불구하고 '한 열'을 강조하는 것은
시리즈를 배열처럼 활용할 수 있기 때문이다.
시리즈에 들어갈 수 있는 데이터 형태로는
* 딕셔너리(Dictionary),
* ndarray,
* 스칼라(Scalar)가 있다.
판다스(Pandas)와 넘파이(Numpy) 라이브러리를 활용해 각각의 예를 진행한다.
코드 밑 설명은 대괄호 속 같은 숫자로 입력했다.

[1] pandas 라이브러리를 불러오고 pandas를 사용할 땐 pd라는 별칭을 사용한다는 의미
[2] numpy 라이브러리를 불러오고 numpy를 사용할 땐 np라는 별칭을 사용한다는 의미
[3] 판다스에서 Series 구조의 데이터 만드는 코드 실행
* 빨간 박스 * data 라는 변수를 선언한 적이 없기 때문에 에러가 난다.
괄호 안의 data는 본인이 생성해둔 데이터를 부르면 된다.
1-1. ndarray

[4] np.random.randn() 함수는 정규분포 (-1부터 1사이)값을 무작위로 추출하는 함수이다.
괄호 안의 5는 5개를 추출한다는 의미이다. 인덱스는 a, b, c, d, e로 설정했다.
[5] [4]에서 만든 시리즈를 부른 상태
[6] [4]에서 만든 index를 확인할 수 있다. (참고) 인덱스 확인: 변수명.index

[8] 리스트 형태로 변수 생성
[9] 시리스 생성 시 [8]을 데이터로 넣고, 인덱스는 1, 2, 3으로 지정
[10] 시리스 생성 시 [8]을 데이터로 넣고 인덱스는 설정하지 않음
ndarray는 Numpy의 다차원 행렬 자료구조 클래스이다.
파이썬의 자료형 중 리스트와 비슷한 출력 형태를 갖고 있다.
파이썬의 리스트와 다른 점은
ndarray는 동일 타입의 원소를 배열로 갖는다는 것이다.
* 파이썬 리스트
[0, 1, 3.14, ‘HacadeMi’] → 한 리스트에 정수, 실수, 문자 가능
* ndarray
np.array([1, 2, 3]) → 정수끼리만 가능
np.array([1., 2., 3.]) → 실수끼리만 가능
1-2. 딕셔너리(Dictionary)
딕셔너리는 대괄호 속에 키와 값으로 이루어져 있는 자료형이다.
{'Key' : Value}
{'키': 값}
{‘Number’ : 7}
{’Name’: ‘Hacademi'}
판다스 자료 구조에서 딕셔너리의 키를 Index로 받는다.
value부분을 리스트 형태로 여러 가지 값을 갖게 되더라도 한 덩어리 들어가게 된다.
※ 그렇지만, 한 공간에 2개 이상의 값이 들어가는 건 좋은 데이터 입력 방법이 아니다.

[11] 딕셔너리로 변수 d를 생성했다. {'키': 값, '키': 값, '키': 값}
[12] 변수 d를 데이터로 받아 시리즈 생성 → 키가 인덱스 출력되는 것을 확인할 수 있다.

[13][14] 행 코드는 [11][12]와 같아 보이겠지만,
딕셔너리의 값을 '실수'로 두었다.
출력된 'dtype'으로 데이터 타입이 float 임을 확인할 수 있다.

[15] 변수 d에는 3개의 값만 들어있었다. 때문에 인덱스를 4개로 설정하면 값이 없는 인덱스는 'NaN'으로 표시된다.
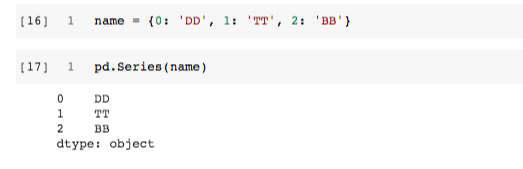
[16] 값을 문자형으로 둔 딕셔너리를 생성했다.
[17] [16]을 데이터로 받아 시리즈를 생성했다.
1-3. 스칼라(Scalar)
값이 하나다.

[18] 실수 7을 데이터로 하고, 인덱스는 a, b, c로 하는 시리즈를 생성했다.
인덱스마다 7.0이 들어가 있다.
[19][20] 정수 7을 데이터로 하는 시리즈를 생성했다. 인덱스를 설정하지 않아 1개의 행만 생겼다.

(가능하지만 나쁜 예)
[21] 하나의 키에 여러 값이 들어가도록 했다. 값 부분을 리스트로 했다.
[21] 시리즈를 생성하면 인덱스 A에 0, 1이 들어가 있다. 엑셀로 치면, 한 셀에 2개의 값이 들어간 것이다.
[23] type() 데이터 타입을 확인할 수 있다. x는 딕셔너리.

[24][25] 시리즈 함수에서 데이터 자리에 문자형을 바로 넣어 생성할 수도 있다.
[26] type()통해 변수 s가 시리즈임을 확인할 수 있다.
'Pandas' 카테고리의 다른 글
| 데이터 구조 | 시리즈(Series), 데이터프레임(DataFrame) - 02 (0) | 2021.10.07 |
|---|